

テキストデータの活用
以下では、PDFファイルに埋め込まれているテキストデータの活用方法について見ていきたいと思います。
テキストの抽出
テキストデータが埋め込まれているPDFファイルからは、テキストを抽出し、別のアプリケーションソフトで使用することができます。
例として、「はじめに」とタイトルがつけられたページの、最初の2つの段落のテキストをコピーしてみます。
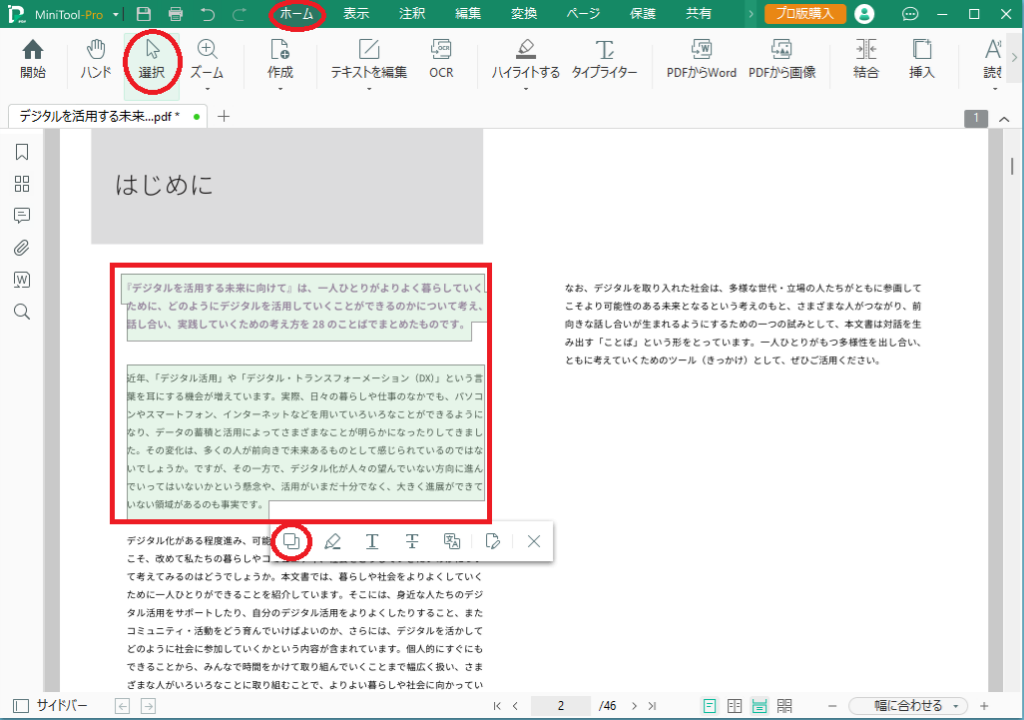
「ホーム」→「選択」をクリックし、コピーしたい文字列をマウスでドラッグして指定します。
マウスの左ボタンから指を離すと、下にいくつかボタンが表示されますので、その1番左の「コピー」ボタンをクリックします。
これで、選択した箇所のテキストがクリップボードにコピーされました。
コピーされたことを確認するために、適当なテキストエディタに貼り付けてみます。
問題なくテキストが貼り付けられました。
PDFファイル上で改行されていた場所に改行が挿入されていますが、改行などの制御文字を置換できるテキストエディタなどを使えば、簡単に改行を削除することができます。

文字数カウント
つづいて、文字数のカウントをしてみたいと思います。
テキストの抽出を行ったときと同様に、文字数をカウントしたい部分を選択し、「表示」→「文字数」をクリックします。
もし、「文字数」というボタンが見つからなかったら、メニューバーの1番右にある「>」のボタンを何度かクリックしてみてください。右に隠れているボタンが1つずつ出てくると思います。
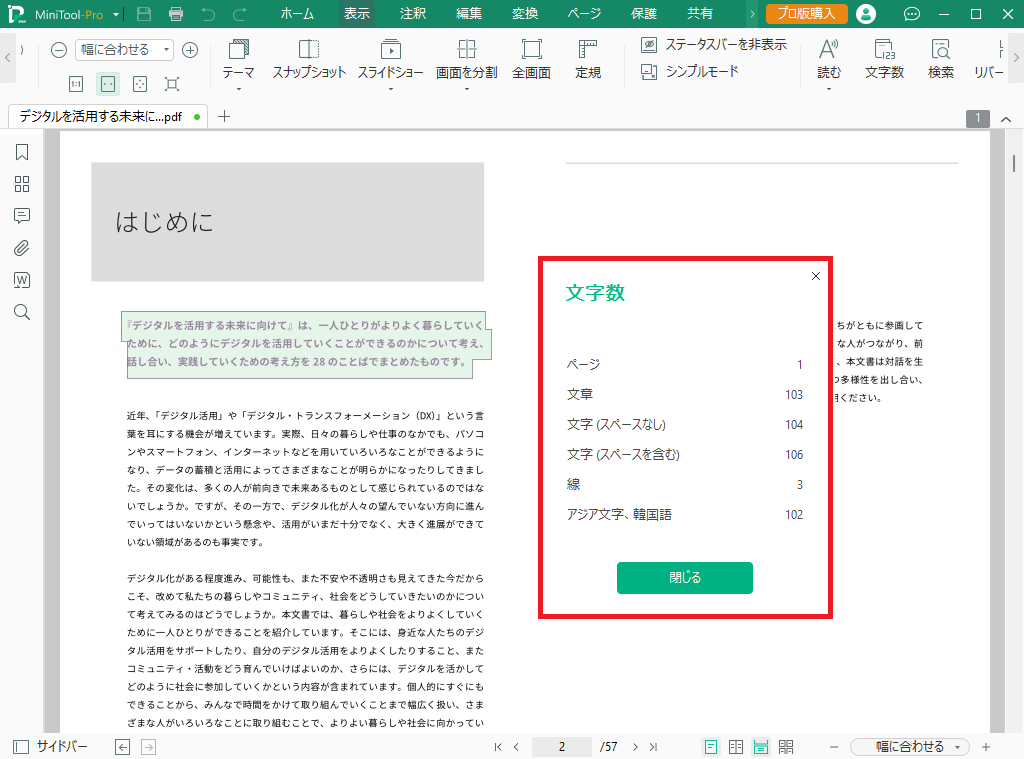
あっという間に文字数が表示されました。
英語などの場合は、文字数でなく単語数をカウントすることになるかと思うので、日本語に対応しているかな?ということが少し気になっていましたが、問題ないようです。
「文章」が103といったあたりが怪しいですが(英語などではここが単語数になるのでしょうか?)、必要な情報は得られていると思います。
読み上げ
つづいて、テキストの読み上げ機能を試してみたいと思います。
漢字には様々な読み方があるため、日本語の読み上げはかなり高度な技術が必要になります。
どこまでの品質か、個人的に非常に興味のあるところです。
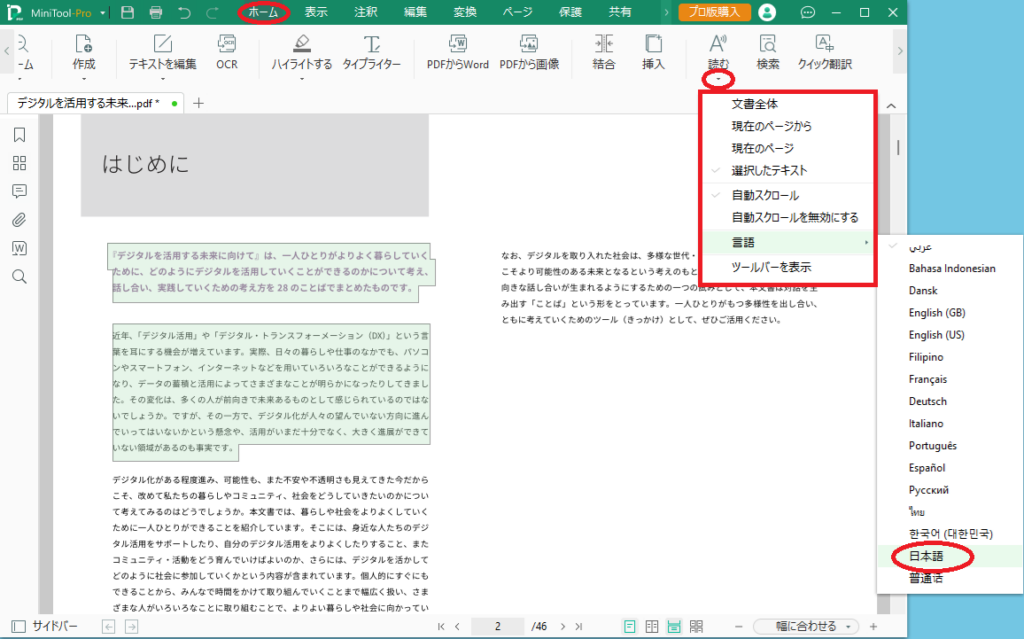
テキストの読み上げを行うには、テキストの抽出を行った時と同様に、読み上げたい部分を選択し、「ホーム」→「読む」のボタンにある「▼」をクリックし、読み上げる範囲を指定します。今回は「選択したテキスト」としました。
次に、読み上げを行っている場所に合わせて、画面を自動でスクロールするかどうかを指定、最後に「言語」を「日本語」と指定します。
抑揚のない棒読み、ところどころ漢字の読みを間違えますが、チューニングをせずにいきなり読ませた結果としては良好ではないでしょうか。
検索、置換
文字列の検索を行うには、「ホーム」→「検索」をクリックし、現れたダイアログボックスにあるテキストボックスの中に検索したい文字列を入力。エンターキーを押します。
今回は、「デジタル社会」という文字列を検索してみました。
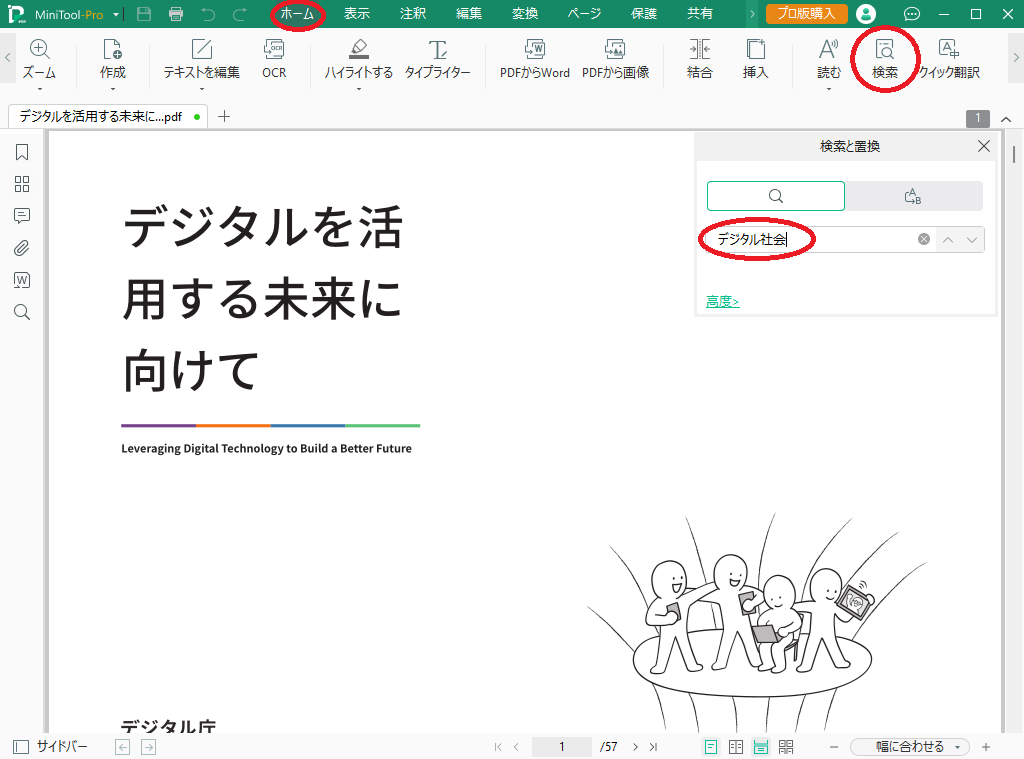
ファイル内を検索した結果、「デジタル社会」という文字列は27個ありました。
次の検索結果、前の検索結果に移動するには、検索する文字列を記入したテキストボックスの右にある上向き、下向きのボタンをクリックします。
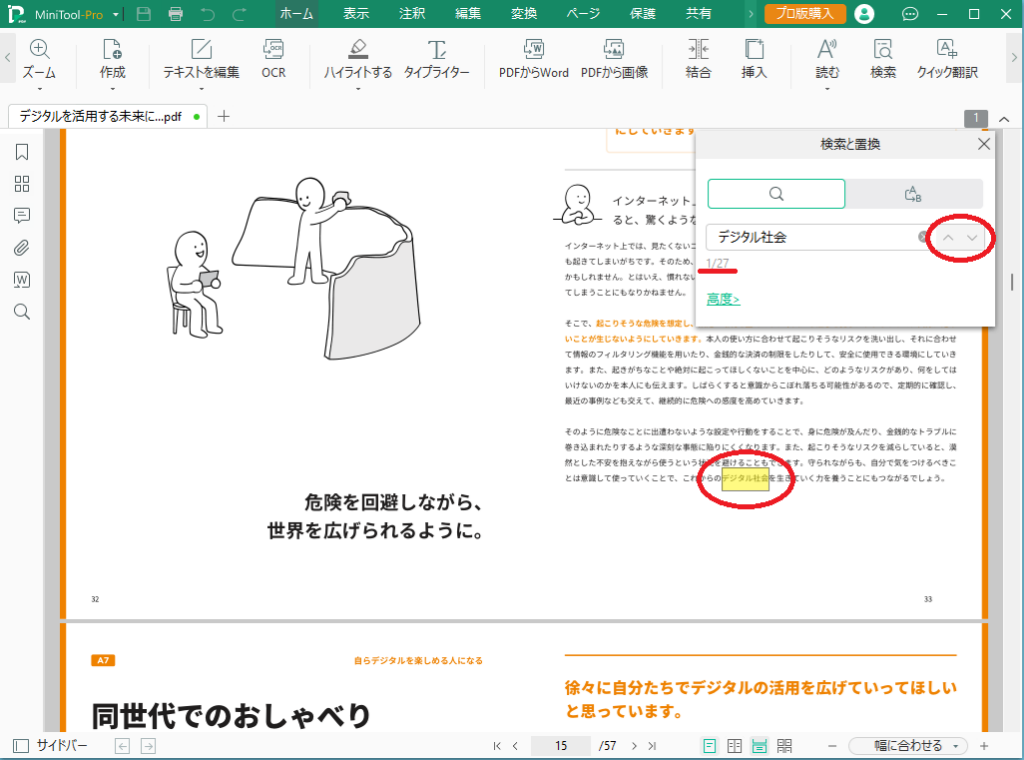
次に置換を行いますが、使用するダイアログボックスは検索の時と同じものです。
検索を行ったときは、虫眼鏡のボタンが選択されていた思いますが、その右のボタンをクリックします。
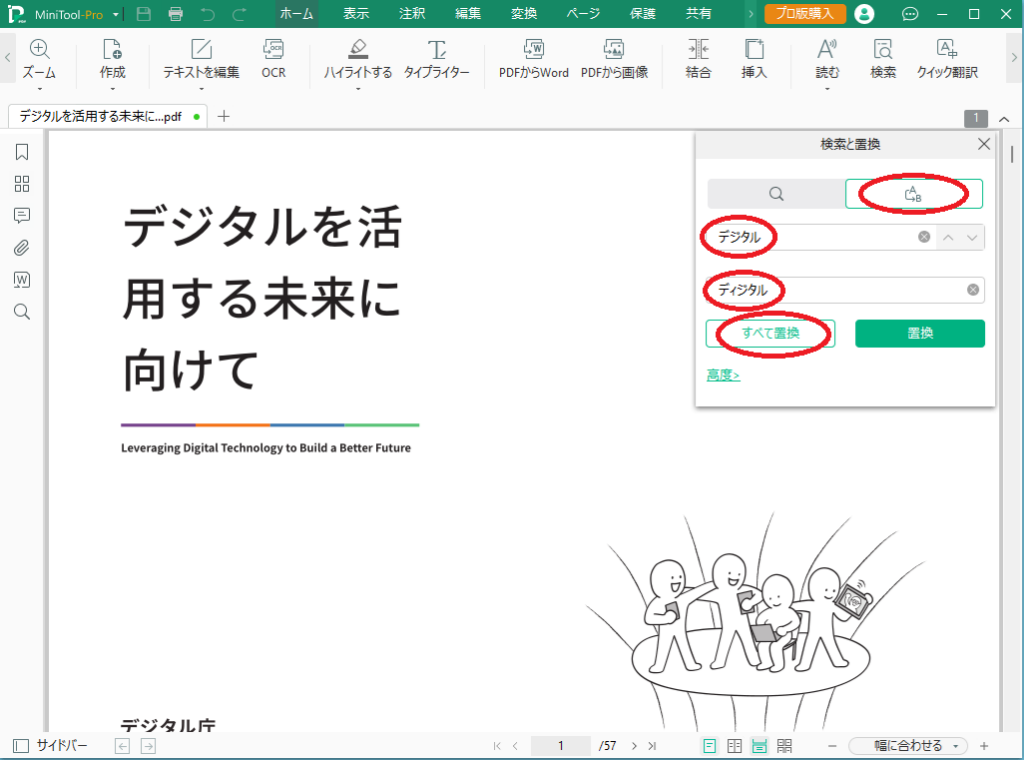
今度は、テキストボックスが2つ表示されたと思います。上が置換前の文字列、下が置換後の文字列です。
例として、置換前の文字列として「デジタル」、置換後の文字列として「ディジタル」を入力し、「すべて置換」をクリックします。
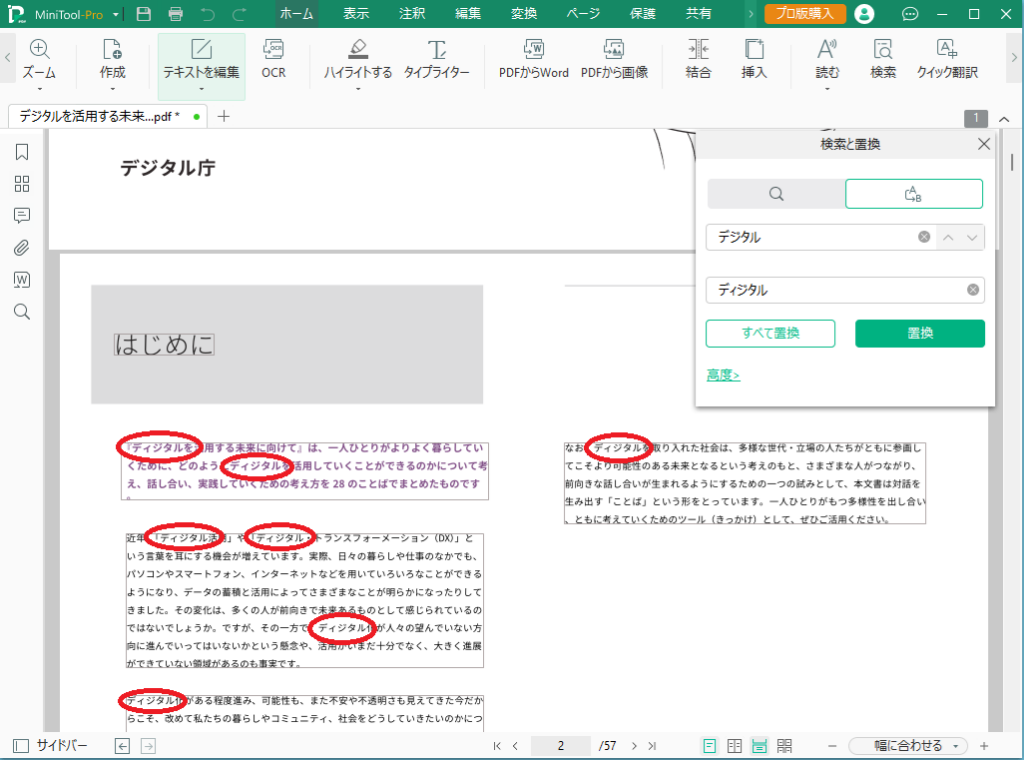
PDFファイル内の「デジタル」が、すべて「ディジタル」に置き換わりました。
本文中の置換した文字列は、以前と同じフォントを保っているようですね。
しかし、1ページ目の見出しの部分は、今回もフォントが崩れていました。


コメント