

OCR(文字認識)
Microsoft Wordや、PowerPointなどからPDFに変換したファイルには、テキスト情報が埋め込まれているのですが、スキャナなどを使って印刷物を読み取ってPDFファイルにした場合、文字列はただの画像データと同じような情報しか持っていません。そのため、全ページで行ったようなテキスト抽出や検索などを行うことができません。
そのようなPDFファイルにテキスト情報を埋め込むためには、OCR(Optical Character Reader)という機能を使って、文字を認識させる必要があります。
『MiniTool PDF Editor』には、そのOCR機能が備わっていますので、試してみたいと思います。
印刷
図と文章がバランス良く混じっているページということで、下に示すページを使いたいと思います。
スキャナで読み込ませるために、このページを1度紙に印刷します。
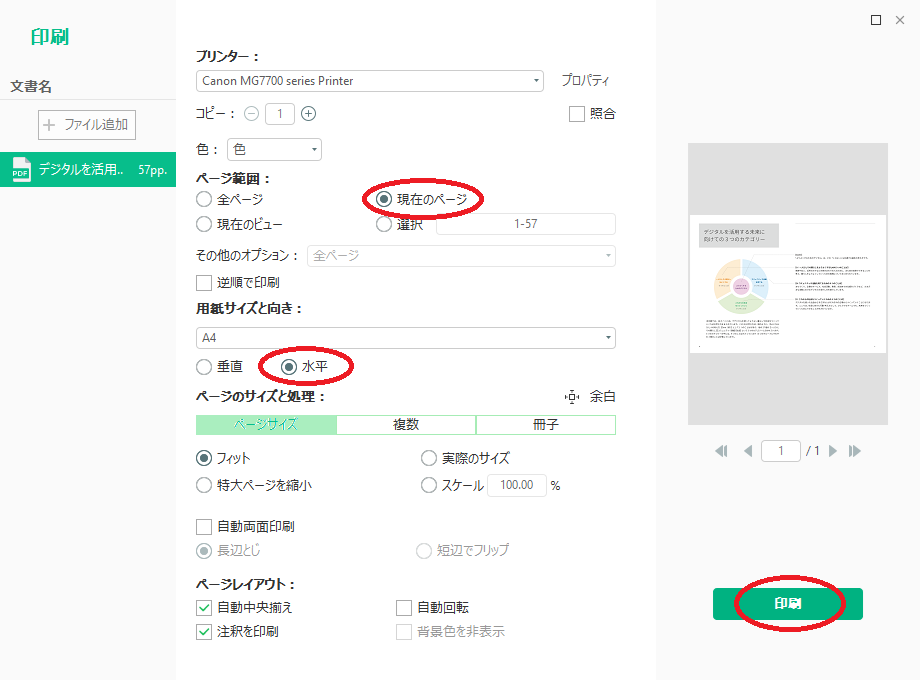
印刷を行うには、タイトルバーにあるプリンターの絵をクリックします。
印刷の設定画面は、普段使用されているものと大きく変わらないと思います。
ただし、用紙の向きは、「縦」が「垂直」、「横」が「水平」と表記されています。
設定が終わったら、右下の「印刷」ボタンをクリックします。
OCR(文字認識)
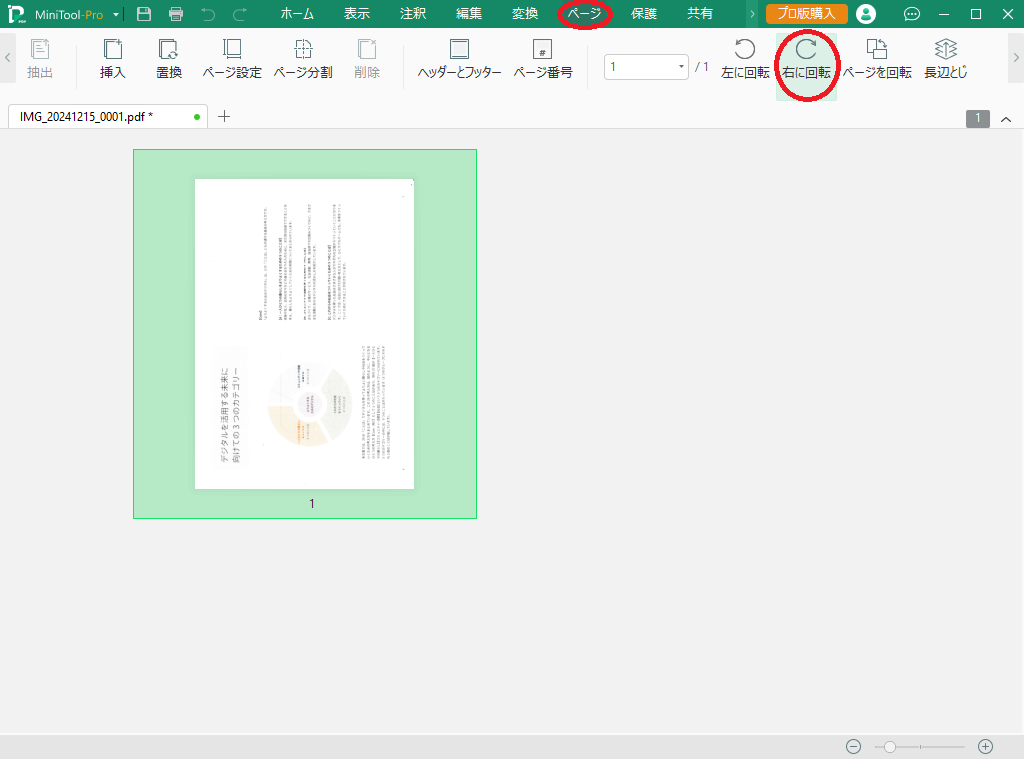
上で印刷したページを、スキャナで読み取ってPDFファイルにしました。
文書が左に90度回転してしまっていたので、修正しておきます。
「ページ」→「右に回転」を1回クリックすると、正しい向きに修正されると思います。
文字列を選択すると、一見選択できたように見えますが、コピーしてテキストエディタに貼り付けても、何も表示されません。
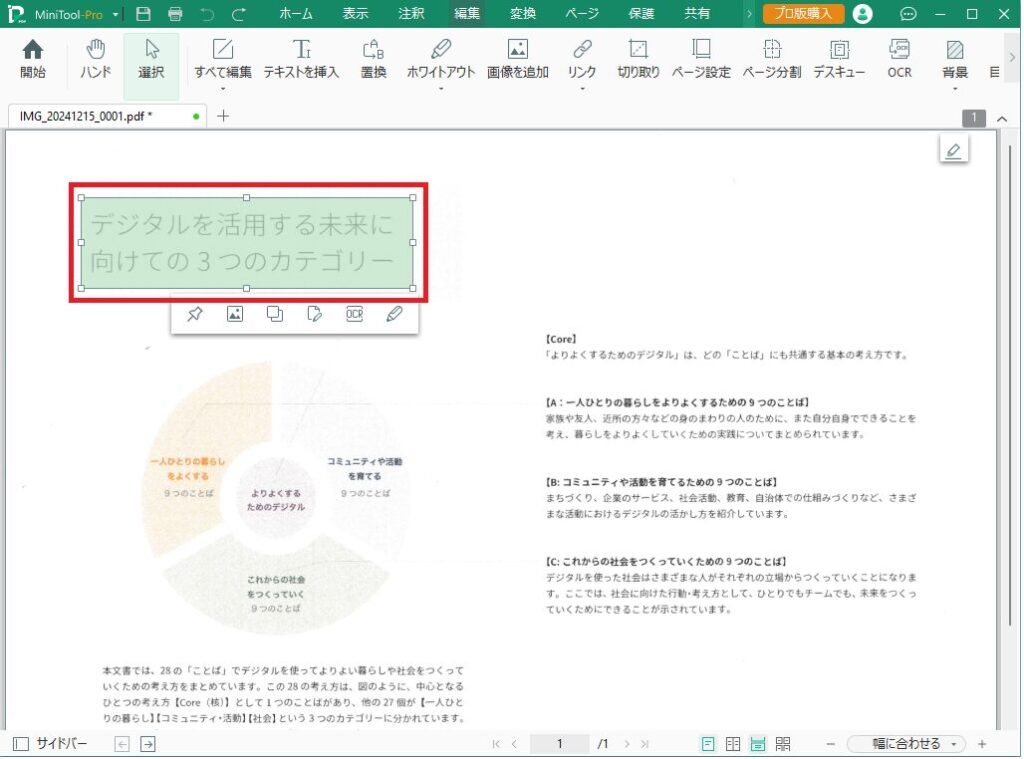
このPDFファイルに対して、OCRをかけてみたいと思います。
「編集」→「OCR」をクリックします。
変更を保存してくださいというダイアログボックスが表示されるので、「保存」をクリックします。

OCRの設定を行うダイアログボックスが表示されます。
「文書言語」は、初期設定では「英語」のみになっているかと思いますので、ドロップダウンリストの中にある「日本語」にチェックを入れておきます。その他の言語が混じっている場合は、その言語にもチェックを入れます。
「出力」は、OCRをかけた結果をどのような形式で出力するかを指定します。
「ページ範囲」は、OCRをかけるページを指定します。時間がかかる処理ですので、まずは少ないページで試すことをおすすめします。
設定が終わったら、「適用」をクリックします。
処理の進行状況が表示されます。
1ページでも、結構な時間がかかります。

処理が終わりました。
1ページの資料が2ページになり、レイアウトも崩れていますね。
円グラフはなくなり、円グラフの下にあった段落も抜け落ちてしまったようです。
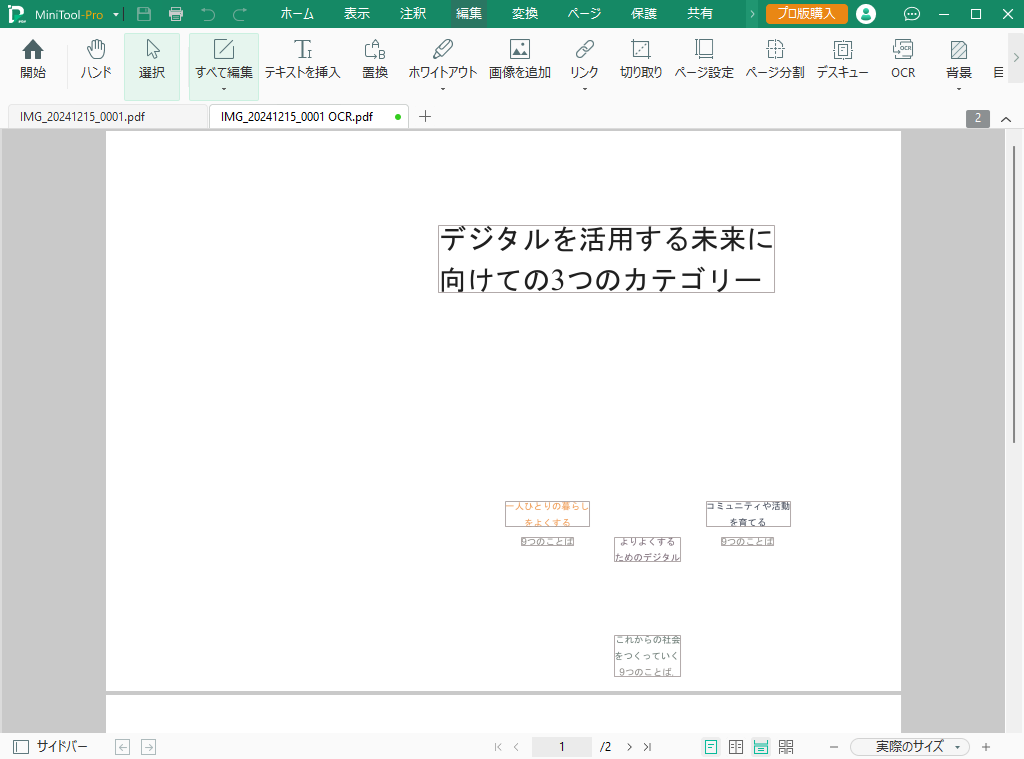
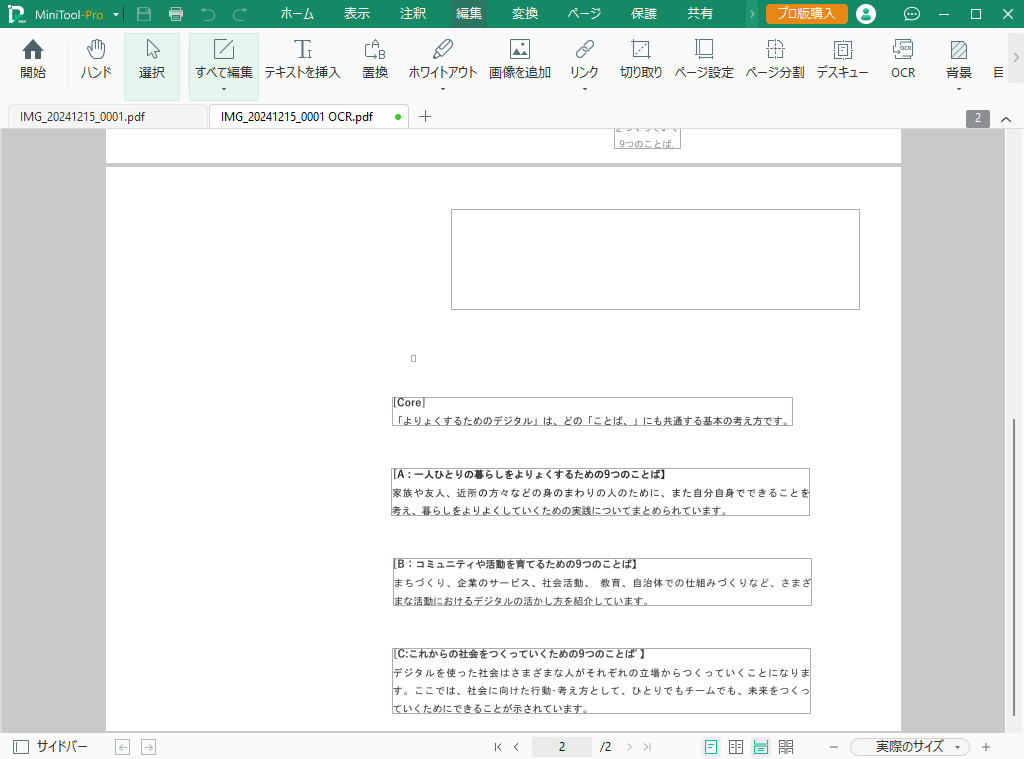
レイアウトのことは置いておいて、文字情報が追加されたか確認してみます。
元のページの右側にあった文章を選択し、コピーします。
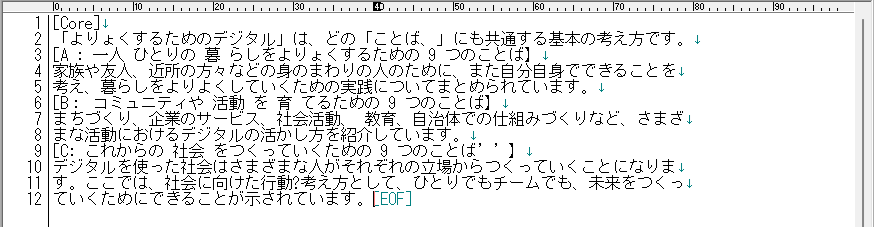
適当なテキストエディタなどを開いて貼り付けを行うと、文章が表示されました。
これで、PDFファイルから、文字情報を抽出することができるようになったことが確認されました。
「よりよく」が「よりょく」となっていたり、途中に半角スペースが入っていたりしますが、精度としては良いのではないでしょうか。


コメント